Peer to Peer Jboss data grid
Introduction
This blogs explains the setup of a distributed cache whose keys and values are dispersed across nodes that are set up to be part of the the cluster. The access to the keys and values from any of the participating nodes is as though its available locally, there is no need for a centralized server ( although it is supported ) to serve up they keys, nodes can join and leave the cluster as they choose to. The grid will attempt to rebalance the load across all the available nodes ( evenly?). 1k word version below
The jgroups.xml file
This is where you go to make the nodes aware of each other’s existence. The main choice staring in your face is the use of TCP or UDP. Not that i am a networking maven, but the one thing i told myself to clamber out of the predicament is for TCP, you would need to know the participating nodes in advance as opposed to UDP where you would just multicast a.k.a self discover. I am currently using TCP, more because this UDP does not seem to penetrate my brain cells, yet.
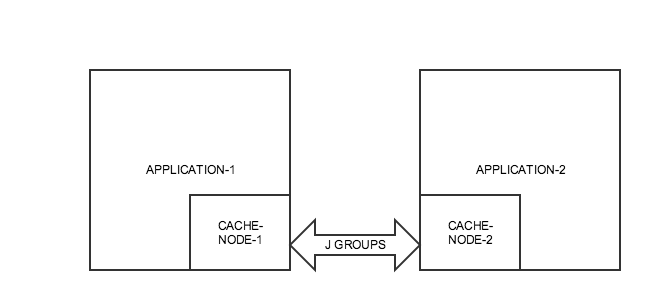
The lone wolf
We will start out process by simply bringing up a solo node with a cache into which we will relentlessly feed keys and values, Its fairly conspicuous that the keys and values will be stored locally. We will print out the count of keys ( we set the flag that will only look for local keys ) and let the key count go to say 100.
The reinforcements
Now that you see this one node busting at the seams with the cache contents, lets send some reinforcemnts in the form of another node. This would join the cluster and share the load. As soon as the node joins the cluster, you would see the cache contents get redistributed as evident by a sudden drop in the cache count in the first node and a corresponding spike in the second. If you care to inspect the details, you can see some of the keys leaving one node and appearing on the other
Sharing is caring
We can extend this concept and add ‘n’ nodes which means more heaps that chip in to carry the load.