Camel split and aggregate with Jboss data grid for persistence
Assumptions
This blog assumes that the user is familiar with infinispan cache/ jboss data grid, camel and J2EE. The focus here is specifically on camel’s features of splitting and aggregating larger data sets.
Introduction
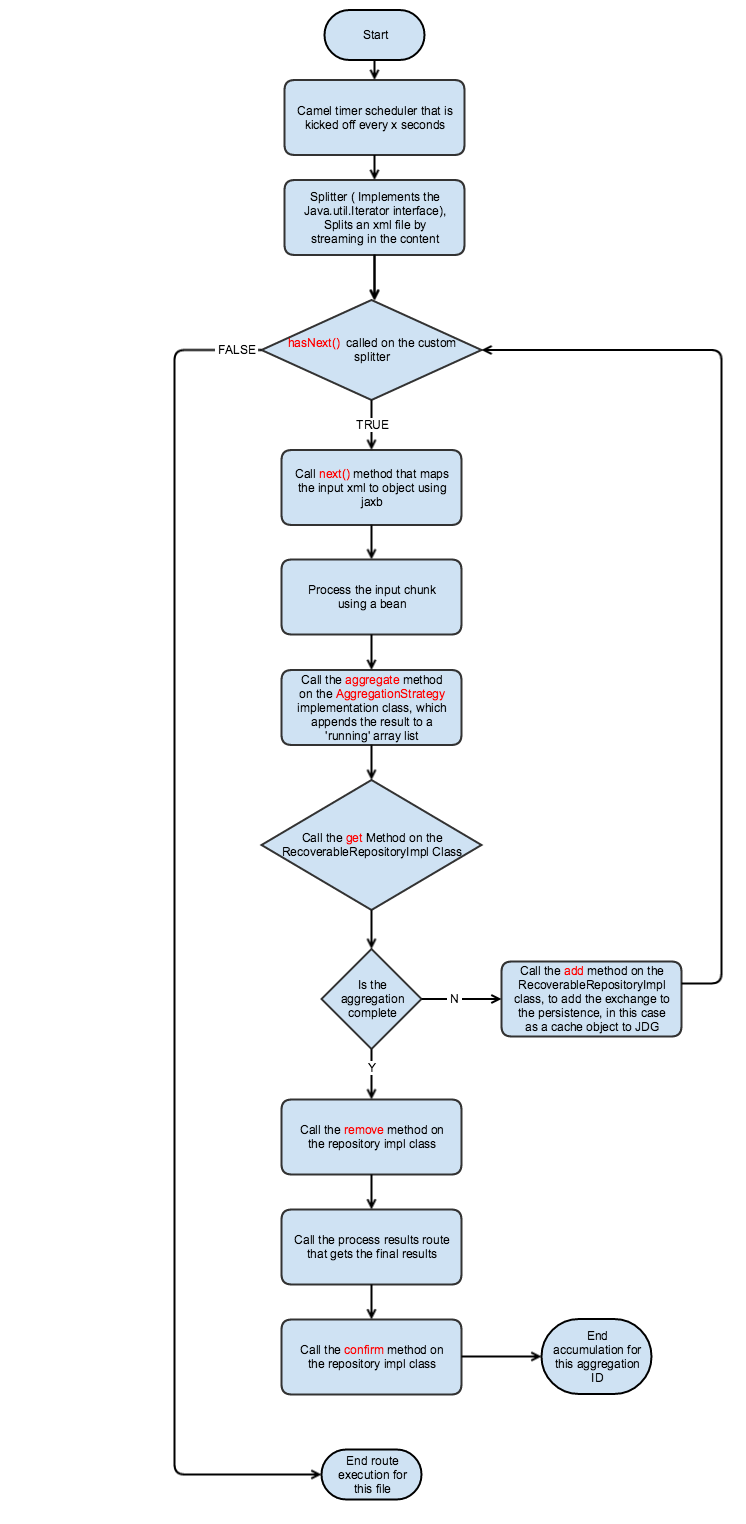
OOTB camel provides a way to split a large file, process it and aggregate the processed chunks, however the process is done in memory that comes with the obvious pitfalls of volatility and availability. If the split and aggregate process needs to be backed up with persistence, then we need to implement the RecoverableAggregationRepository. There are already implementations out there for leveldb and hazelcast, this blog helps you set it up with jboss data grid, another popular key/value pair type cache/object store.
The splitter
The very first step in the process is the splitter which will split a file into chunks with size of our choosing, to implement a customized splitter, we need to have a class that implements the java.util.Iterator interface. Camel will then call the next, hasNext etc for each of the camel route blocks that follow the splitter call. Since the call iterates, its an excellent way to stream in large files, for instance in our example we can stream in an xml file by node.
The processing
The processing bean acts on the body created in the splitter call, it will most likely end up putting the processed results back into the exchange body.
Aggregation
The aggregation process then kicks off at the tail end of the chunk processing, first camel calls the implementation of AggregationStrategy ( implemented inline as a private static class ArrayListAggregationStrategy ) , after this method execution is complete camel checks to see if there is a key/value pair in our persistence store (JDG) by calling the get method on the class implementing RecoverableAggregationRepository ( In our case this is RecoverableAggregationRepositoryImpl ). The next step in the process would be a call to the add method on the same class, Since our strategy is to keep aggregating to the Arraylist,after every call, the arraylist represents the current and transient set of results accumulated.
Persistence
As the title of the blog states, persistence is achieved by implementing RecoverableAggregationRepository interface, and the methods of particular relevance are add,get,remove and confirm, what’s passed to them has to be saved, removed, retrieved etal, this is where we call the CRUD methods on JDG. One wrinkle to this is that we arent just saving what we get in the method calls, another way of putting it is that the add method expects us to save the exchange, but it would be nice to be able to see what is going on in this persistence, when was something persisted, all the exchanges meeting a certain criteria yada yada.. say hello to JDG object persistence.
Object stores
JDG provides a way of storing objects in a remote server using google’s own protobuf protocol, a monster topic in itself but the singular and salient point of relevance is it can store serializable objects. You can check out some code here, if you looking for some play dough. JDG remote queries. In this case i am storing what the camel repository needs and some other metadata that would help me probe the system by inspecting the data.
Code and setup
- Download the jboss data grid server, using 6.4 for this tutorial
- Start the jboss data grid server by running the following command
<download directory>/jboss-datagrid-6.4.0-server/bin/standalone.sh
- The jdg cache that we will use for this purposes is ‘default’ which comes with the installation
- I am using fuse 6.2.1 ( on EAP platform ) as the server hosting it.
- Start the fuse server by running
<fuse installation>/EAP-6.4.0/bin/standalone.sh
- The simple implementation, showing this concept is is checked into github source
- To run the program using maven, plese run mvn clean install ( it has a built in plugin that will deploy the application to localhost)
- After every 30 seconds, the scheduler gets kicked off and you can see the steps in the flow chart get executed.